Resources
The following resources are provided free and without warranty. Some are GPLed, most of them come unlicenced.
Almost all Praat plugins and scripts listed here are based on the current Praat scripting syntax. To run them you need a current version of Praat (version 5.3.64 or newer).
Got a taste for Praat scripting? Visit my Praat scripting tutorial Phonetics on Speed and learn how to code your own scripts or adapt and improve scripts written by others.
 If you are interested in the acoustic analysis of the human voice have a look at VOXplot. We have developed VOXplot with the aim of providing a tool for acoustic voice analysis that is based on proven and reliable algorithms (using Praat in the background) and at the same time easy and intuitive to use. VOXplot is open source, written in Python, and available for free for Windows, macOS and Linux. Find out more!
If you are interested in the acoustic analysis of the human voice have a look at VOXplot. We have developed VOXplot with the aim of providing a tool for acoustic voice analysis that is based on proven and reliable algorithms (using Praat in the background) and at the same time easy and intuitive to use. VOXplot is open source, written in Python, and available for free for Windows, macOS and Linux. Find out more!
Content
Praat Scripts
Praat Plugins
Editor Plugins
NCHLT Plugin
This plugin enables Praat to search in the orthographic transcriptions of the NCHLT Speech Corpus and open the audio files of corresponding search results.
The NCHLT Speech Corpus (National Centre for Human Language Technologies, Council for Scientific and Industrial Research, South Africa) contains orthographically transcribed broadband speech corpora for all of South Africa’s eleven official languages and must be available on your machine (at least one language) before using this plugin. The corpus can be obtained from the South African Centre for Digital Language Resources (SADiLaR) website.
After launching this plugin, you select one of your installed languages and specify a search pattern (simple pattern or regular expression). XML parsing and search is done inside the Praat script (this is considerably slower but more robust than doing it with Python like before). You can view the results in a table (including orthographic transcription, speaker ID, age, gender, and location) and open corresponding audio files one after the other or specifically for certain items in the results list. It’s also possible now to refine the search results using filters (age, gender, and location).
Download
- The plugin is available on Github:
https://github.com/jouml/NCHLT-Praat-Plugin
Recquirements
- Praat 5.4.x or newer
- NCHLT Speech Corpus (at least one language)
Changelog
- v1.0
- support for new SADiLaR folder naming pattern
- available on Github
- v0.4
- detailed manual added
- v0.3
- Python no longer required
- regular expression search
- filtering of search results
- v0.2
- usability improvements and bug fixes
- v0.1
- initial release
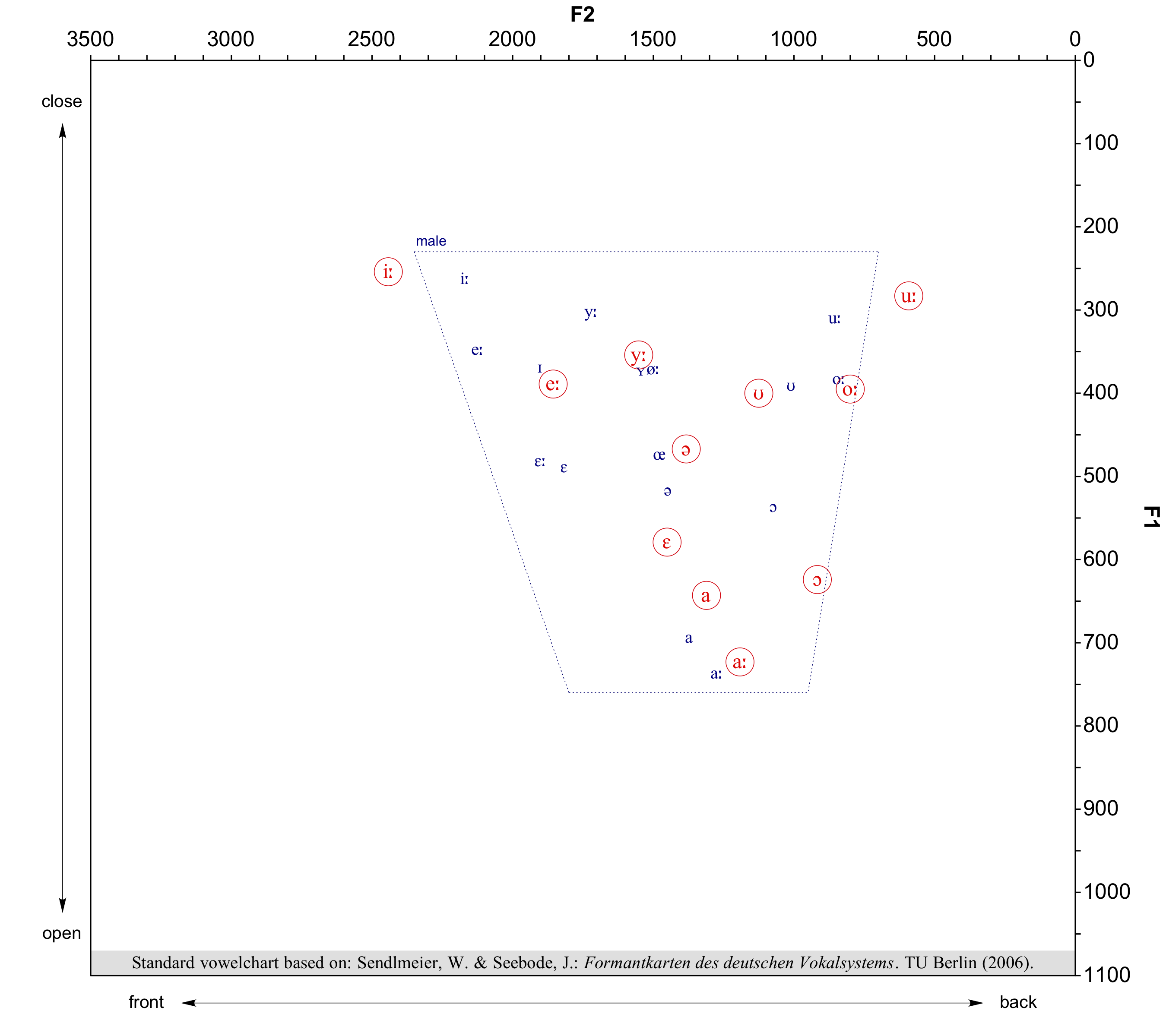
Vowelchart
With this plugin, you can first intialize a Praat picture for a F1/F2 vowelchart (option: show german standard vowelchart). You can then add measured formant values with the appropriate symbols to the chart (options: symbol, color, circle around symbol). Here’s an example with the German standard vowelspace for male speakers in blue and some measured vowels in red:
Pitch settings
Editor script implementing Hirst’s (2011) two-pass approach to set pitch analysis parameters for Praat’s pitch algorithm.
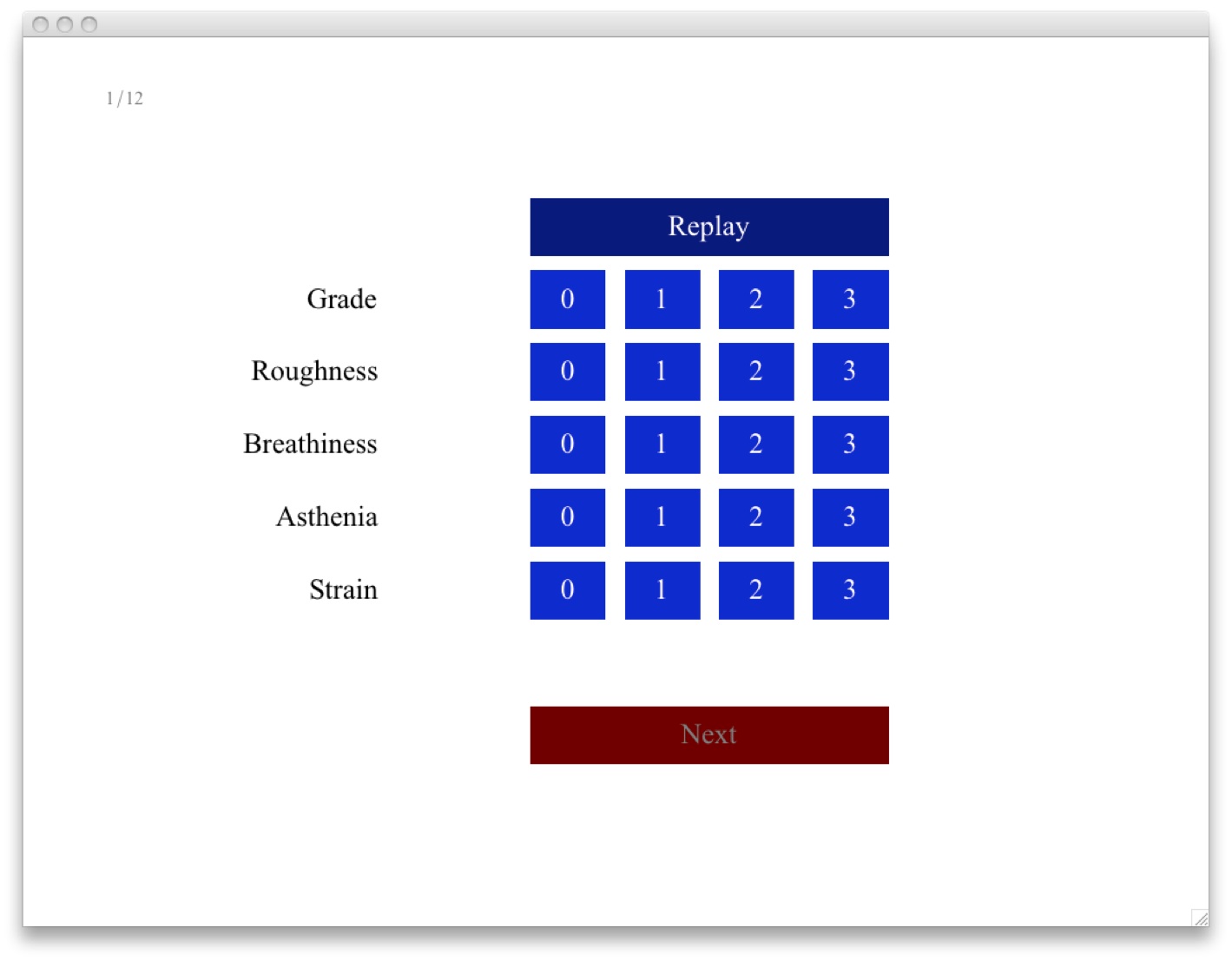
GRBAS voice quality assessment
Demo window application (pretty raw) that implements the GRBAS voice quality assessment (Grade, Roughness, Breathiness, Asthenia, Strain). Randomized presentation of wav files, evaluation form with 4 levels per dimension.
Extract intervals
The script finds all non-empty intervals in the selected TextGrid, extracts the corresponding sound segments from the associated sound object, and saves the segments to the hard disk. Intervals with certain labels can be excluded with a search pattern. Three options for the filenames:
- label of the segment (label.wav)
- index (001.wav)
- index + label (001_label.wav)
Concatenate sounds
Implements concatenation of two or more sounds with optional pause (silence) between sounds and optional custom order (standard order is the order of objects in the objects list). If the selected sounds have different sampling frequencies the script asks for permission to resample before concatenation (only sounds with the same sampling frequency can be concatenated).
Plot data and trendline
The first script plots raw data from a table as line graph or scatter plot and adds a trendline based on a simple linear regression analysis (Praat built-in method). You can select various graphics options (color, line style, data symbols etc.). The second script adds a trendline to an existing data plot.
MFC wizard
Generates a syntactically correct experiment file for ExperimentMFC after prompting the user for all relevant parameters. Requires ExperimentMFC version 6 (introduced in Praat 5.3.36).
Sessions for Praat
This plugin implements a simple session management system for Praat. A session is a distinct accumulation of objects (any type, any number) in the objects list. With this plugin, all objects in the list are saved to the session (a binary Praat collection), whether selected or not. All sessions are saved to a default directory. The default directory is specified only once and then memorized.
If you just want a simple and fast method to save and restore a bunch of objects use this plugin. If you want your sessions distributed among different directories (e.g. put sessions for individual projects in different project directories) use the standard Praat procedure for saving Praat collections. Of course, both methods can be combined.
Additional plugin features:
- existing session: overwrite or append objects
- open session and remove collection file at one go
- list and remove existing sessions (dropdown menu)
- (re-)set default directory
Sublime Text plugin
Praat comes with a built-in script editor which is pretty simple. If you are familiar with other code editors you may miss some productivity features, like e.g. syntax highlighting, automatic indentation, bracket matching, snippets etc. Fortunately, most serious editors provide a plugin mechanism to add extended functionality, enabling you for instance to teach them a new language.
My prefered code editor, Sublime Text, comes with many helpful language-independent features (multi-selection/multi-edit, sophisticated find and replace, projects, etc.). To utilize Sublime’s language-dependent skills as well—in particular syntax highlighting and the build system—this plugin teaches Sublime Text the Praat scripting language.
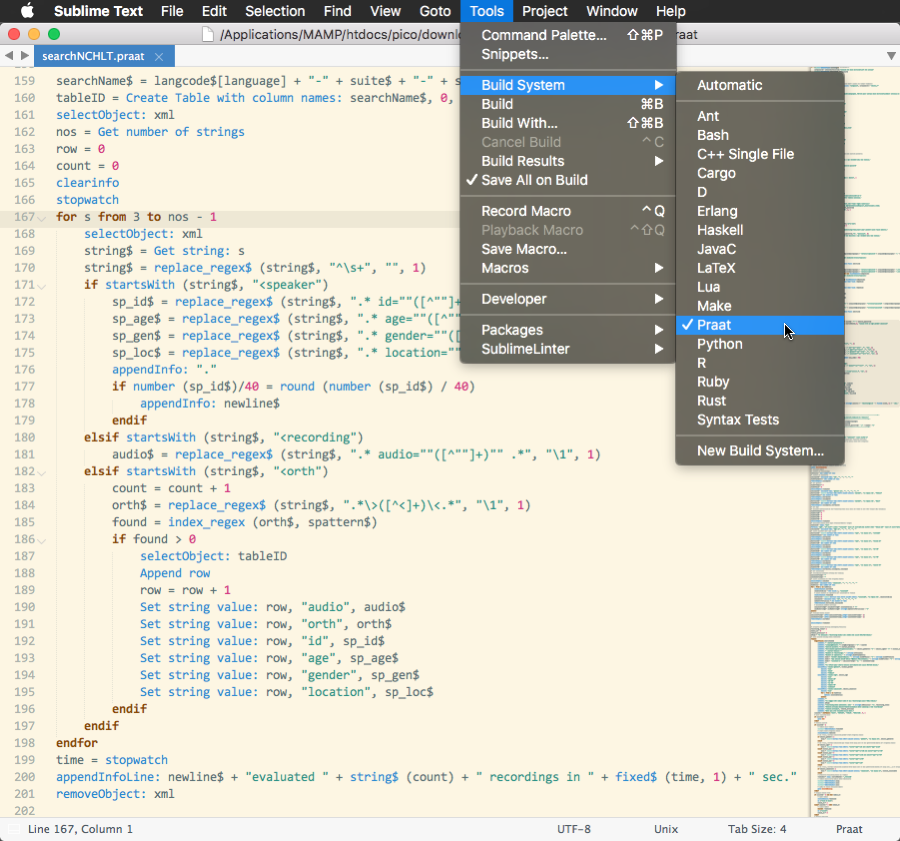
The plugin includes the following Praat specific stuff:
- comments definition
- indent patterns
- some snippets (if you need even more snippets create your own or check Mauricio Figueroas plugin; see below)
- language definition reflecting the recent scripting syntax (starting with Praat 5.3.63; older syntax versions are more or less supported)
- customized Solarized Light theme
- build system
Using the build system, you can run your Praat scripts from within Sublime Text (
If you use a Praat version older than 6.2.05 the build system relies on sendpraat, a command line utility which is available from the Praat homepage: sendpraat. To activate sendpraat navigate to the plugin directory, then
- Mac/Linux: edit runPraatScript.sh
- Windows: edit runPraatScript.bat
To install the plugin, unpack the zip file to your
Requirements
- Sublime Text 3 or 4 (not tested with Sublime Text 2; it may work…)
- sendpraat command line utility (only with Praat < 6.2.05)
Changelog
- v0.6
- --send switch instead of sendpraat as default (Windows)
- v0.5
- --send switch instead of sendpraat as default (Linux/Mac)
- language definition refinements
- v0.4
- licence added
- v0.3
- bug fixes
- v0.2
- language definition refinements
- v0.1
- initial release
Other editor plugins
José Joaquín Atria has written a language definition for the Editor Kate (available on GitHub). Mauricio Figueroa provides a language definition and snippets for Sublime Text (available on GitHub). Stefano Coretta converted Mauricios stuff into an language package for Atom. Scott Sadowsky provides a syntax highlighting file for Notepad++. And there’s a syntax file for Vim from Mart Lubbers. Last but not least, Ace, the embeddable code editor written in JavaScript, masters Praat syntax highlighting.